C# and OpenXml (.Net 5) tutorial, In this post, I will explain how to use OpenXml in C# in a .NET 5 project. This project is a simple openxml convert to pdf, it extracts images from a Pdf and Word document with the use of word processing document Open Xml. You can extract images from any document type, you can convert openxml Pdf to word, openxml html to pdf, openxml convert pdf to html, openxml docx to pdf, doc to html, openxml convert to pdf or to many conversion types, using c# application (c# openxml to pdf). This Openxml tutorial is a great documentation you can use it as a sample example in your programming, for any feedback or comment or question please leave it in the comments below.
Please subscribe to our YouTube channel and stay updated with our new released videos
First, create a .NET 5.0 WinForms project, and add the DocumentFormat.OpenXml and GroupDocs.Parser
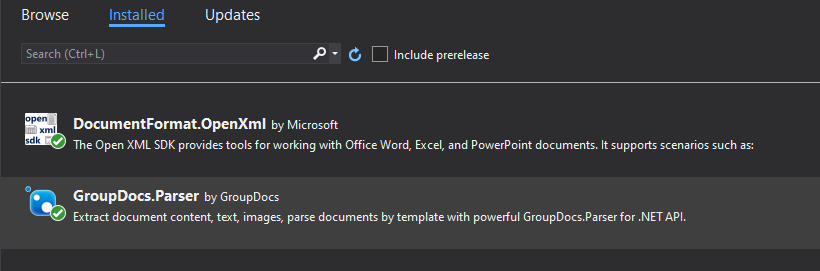
After you add these packages in your project, you are able to begin building your .NET windows forms.
My main form looks like that
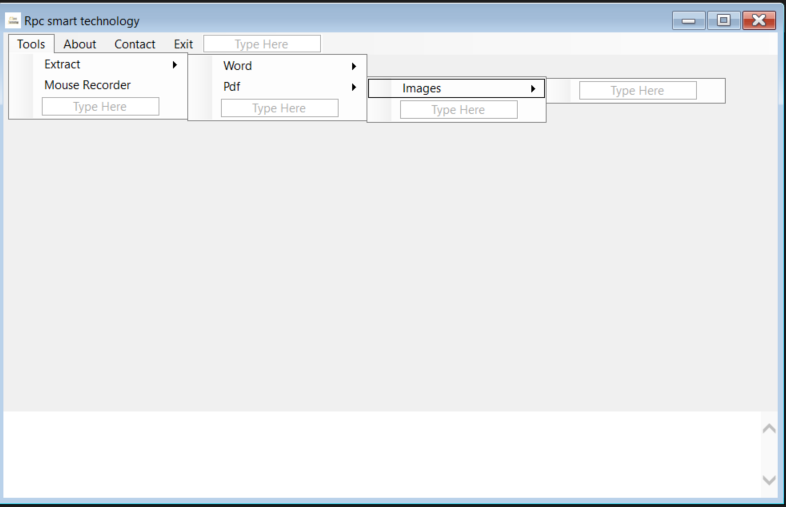
Extract -> Pdf -> Images (double click images), the code behind for extracting images for pdf opens.
private void imagesToolStripMenuItem2_Click(object sender, EventArgs e)
{
var frm = new frmPdfExtractImages();
frm.Show();
}The frmPdfExtractImages is the form for Pdf image extraction
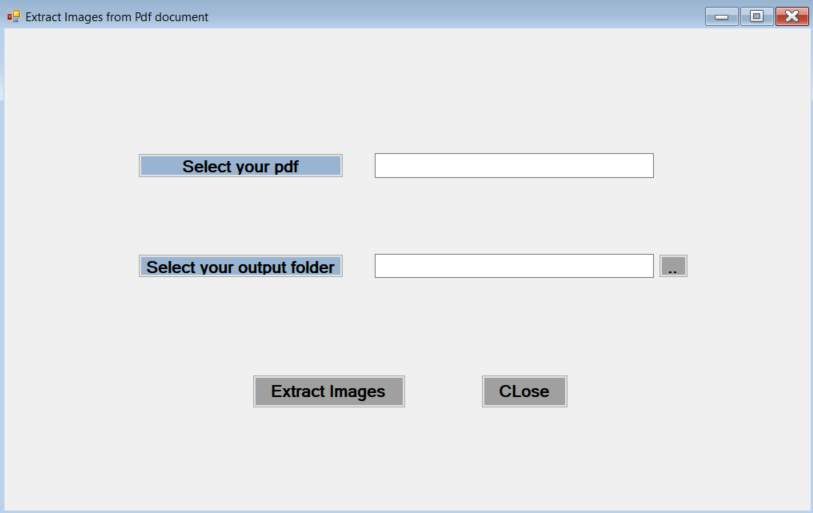
Double click the button “Select your pdf”, this button open a file dialog where you can choose your pdf source file.
private void btnSource_Click(object sender, EventArgs e)
{
OpenFileDialog openFileDialogPdf = new OpenFileDialog();
openFileDialogPdf.CheckFileExists = true;
openFileDialogPdf.CheckPathExists = true;
openFileDialogPdf.Multiselect = false;
openFileDialogPdf.Filter = "Pdf Files|*.Pdf;";
if (openFileDialogPdf.ShowDialog() == DialogResult.OK)
txtSource.Text = openFileDialogPdf.FileName;
}Double click “Select your output folder”, this button open destination folder where the extracted images will reside.
private void btnDest_Click(object sender, EventArgs e)
{
FolderBrowserDialog folderDlg = new FolderBrowserDialog();
folderDlg.ShowNewFolderButton = true;
// Show the FolderBrowserDialog.
DialogResult result = folderDlg.ShowDialog();
if (result == DialogResult.OK)
{
txtDestination.Text = folderDlg.SelectedPath;
Environment.SpecialFolder root = folderDlg.RootFolder;
}
}Double click the 2 dots button, it opens the destination folder:
private void btnShowOutput_Click(object sender, EventArgs e)
{
if (txtDestination.Text != "")
{
openFileDialogPdf.InitialDirectory = txtDestination.Text;
openFileDialogPdf.ShowDialog();
}
else
MessageBox.Show("You must select a folder");
}Double click the “Extract images” button, the code behind this button, process the document with OpenXML and extrac the images from the document.
private async void btnExtract_Click(object sender, EventArgs e)
{
if (txtSource.Text != "" && txtDestination.Text != "")
await Task.Run(() => GetGraphFromReport(txtSource.Text, txtDestination.Text));
else
MessageBox.Show("Please provide a valid source file and destination folder");
}GetGraphFromReport is the main function to extract the images from the document, it has 2 parameters, the source file and destination folder, it process the source file images using the openXml and GroupDocs.Parser and extract the images to the destination folder.
public static async Task<bool> GetGraphFromReport(string inputFile, string outputFolder)
{
try
{
if (isProcessing == false)
{
isProcessing = true;
byte[] doc = File.ReadAllBytes(inputFile);
Stream stream = new MemoryStream(doc);
using (Parser parser = new Parser(stream))
{
// Extract images
IEnumerable<PageImageArea> images = parser.GetImages();
if (images == null)
MessageBox.Show("Images extraction isn't supported");
int counter = 1;
// Iterate over images
foreach (PageImageArea image in images)
{
// Save each image
Image.FromStream(image.GetImageStream()).Save(string.Format($@"{outputFolder}\\{counter}.Jpeg", counter++), System.Drawing.Imaging.ImageFormat.Jpeg);
}
if (images.Count() > 0 && counter - 1 == images.Count())
MessageBox.Show("All Images extracted successfully");
else if (images.Count() > 0 && counter - 1 != images.Count())
MessageBox.Show("Not all Images extracted successfully");
else
MessageBox.Show("No images found to extract");
isProcessing = false;
return true;
}
}
else
return false;
}
catch (Exception ex)
{
MessageBox.Show("Error : " + ex.Message);
return false;
}
}OpenXML SDK
The Open XML documentation SDK provides tools for working with Office Word, Excel, and PowerPoint documents. It supports scenarios such as:
– High-performance generation of word-processing documents, spreadsheets, and presentations.
– Populating content in Word files from an XML data source.
– Splitting up (shredding) a Word or PowerPoint file into multiple files, and combining multiple Word/PowerPoint files into a single file.
– Extraction of data from Excel documents.
– Searching and replacing content in Word/PowerPoint using regular expressions.
– Updating cached data and embedded spreadsheets for charts in Word/PowerPoint.
– Document modification, such as removing tracked revisions or removing unacceptable content from documents.
You can watch this C# and OpenXml documentation (.Net 5)tutorial on YouTube channel
Rpc Technology
http://RpcHost.com